什么是LSA
LSA(Latent Semantic Analysis), 潜在语义分析。试图利用文档中隐藏的潜在的概念来进行文档分析与检索,能够达到比直接的关键词匹配获得更好的效果。
关键词匹配进行文档检索有何问题?
现在我们考虑检索问题,我们要从一些文档(可以是一句话、一个段落或一篇文章)中检索出我们想要的文档,可以想到的最简单的方法就是关键词匹配,即哪篇文档包含我们检索使用的关键词,我们就认为该文档是我们想要的。这样做当然可以,但存在如下两个问题。
问题一
我们知道,无论在英语还是汉语中,一个词语或一个单词都存在同义词,比如愉悦和开心,那么通过关键词检索愉悦,就只能找到包含愉悦这两个字的文档,而不能找到包含开心但不包含愉悦的文档。撇开同义词,当我们检索乔布斯,我们可能也想检索到关于iphone的相关信息,但仅通过关键词匹配,不能检索到。
问题二
我们知道,无论在英语还是汉语中都存在一词多义问题,比如“苹果”,到底指的是一种水果还是一个手机品牌,除非给定上下文语境否则我们不得而知。这样仅通过关键词匹配,检索到的含义可能不是我们想要的。撇开一词多义,文档中可能存在很多词语属于拼写打字错误(粗心)、误用(语文没学好)、巧合(比如“和服装”,这里的和服不是一个词语,但关键词匹配会检索到),更甚,文档中可能存在大量广告信息,人为植入这些关键词,这些都不是我们想要的。
LSA可以完全解决上述问题吗?
不能。
LSA可以很好的应对上述问题一,对于问题二不能彻底解决。
LSA的核心思想
假设有 $n$ 篇文档,这些文档中的单词总数为 $m$ (可以先进行分词、去词根、去停止词操作),我们可以用一个 $m*n$ 的矩阵 $X$ 来表示这些文档,这个矩阵的每个元素 $X_{ij}$ 表示第 $i$ 个单词在第 $j$ 篇文档中出现的次数(也可用tf-idf值)。下文例子中得到的矩阵见下图。
LSA试图将原始矩阵降维到一个潜在的概念空间(维度不超过 $n$ ),然后每个单词或文档都可以用该空间下的一组权值向量(也可认为是坐标)来表示,这些权值反应了与对应的潜在概念的关联程度的强弱。
这个降维是通过对该矩阵进行奇异值分解(SVD, singular value decomposition)做到的,计算其用三个矩阵的乘积表示的等价形式,如下:
$$
X = U{\Sigma}V^T
$$
其中 $U$ 为 m * n 维,$\Sigma$ 为对角阵 n * n 维,$V$ 为 n * n 维。
$\Sigma$ 矩阵中对角线上的每一个值就是SVD过程中得到的奇异值,其大小反映了其对应的潜在概念的重要程度。
然后我们可以自行设定降维后的潜在概念的维度 $k(k < n)$ , 可以得到:
$$
X_k = U_k\Sigma_kV_k^T
$$
其中 $U_k$ 是将 $U$ 仅保留前 $k$ 列的结果,$\Sigma_k$ 是仅保留前 $k$ 行及前 $k$ 列的结果,$V_k$ 是将 $V$ 仅保留前 $k$ 列的结果。
$X_k$ 则是将 $X$ 降维到 $k$ 维的近似结果,这个 $k$ 越接近 $n$, $X_k$ 与 $X$ 也越接近,但我们的目标并不是越接近越好,LSA认为 $k$ 值不宜过大(保留了冗余的潜在概念)也不宜过小。
LSA如何实现
这里用python结合一个例子来实现一个LSA。
1 定义一些变量
待处理的文档
选用的documents来自wikipedia,包含海贼王里zoro、luffy、nami三个人的人物介绍。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 文档
documents =[
"Roronoa Zoro, nicknamed \"Pirate Hunter\" Zoro, is a fictional character in the One Piece franchise created by Eiichiro Oda.",
"In the story, Zoro is the first to join Monkey D. Luffy after he is saved from being executed at the Marine Base. ",
"Zoro is an expert swordsman who uses three swords for his Three Sword Style, but is also capable of the one and two-sword styles. ",
"Zoro seems to be more comfortable and powerful using three swords, but he also uses one sword or two swords against weaker enemies.",
"In One Piece, Luffy sails from the East Blue to the Grand Line in search of the legendary treasure One Piece to succeed Gol D. Roger as the King of the Pirates. ",
"Luffy is the captain of the Straw Hat Pirates and along his journey, he recruits new crew members with unique abilities and personalities. ",
"Luffy often thinks with his stomach and gorges himself to comical levels. ",
"However, Luffy is not as naive as many people believe him to be, showing more understanding in situations than people often expect. ",
"Knowing the dangers ahead, Luffy is willing to risk his life to reach his goal to become the King of the Pirates, and protect his crew.",
"Adopted and raised by Navy seaman turned tangerine farmer Bellemere, Nami and her older sister Nojiko, have to witness their mother being murdered by the infamous Arlong.",
"Nami, still a child but already an accomplished cartographer who dreams of drawing a complete map of the world, joins the pirates, hoping to eventually buy freedom for her village. ",
"Growing up as a pirate-hating pirate, drawing maps for Arlong and stealing treasure from other pirates, Nami becomes an excellent burglar, pickpocket and navigator with an exceptional ability to forecast weather.",
"After Arlong betrays her, and he and his gang are defeated by the Straw Hat Pirates, Nami joins the latter in pursuit of her dream."
]
定义停止词
我们知道,无论是中文还是英文,有些词语不包含实际的语义,出现在大部分的文档之中,比如量词a,连词and,人称代词I,介词in等等,因此我们认为这些词对于文档的分析没有帮助,将其排除。
1 | stopwords = ['a','an', 'after', 'also', 'and', 'as', 'be', 'being', 'but', 'by', 'd', 'for', 'from', 'he', 'her', 'his', 'in', 'is', 'more', 'of', 'often', 'the', 'to', 'who', 'with', 'people'] |
定义要去除的标点符号
我们知道,英文中单词之前有空格和标点符号隔开字符,因此英文的分词非常容易,只要把粘连的标点与单词隔开就可以了。对于中文,需要先进行分词。1
2# 要去除的标点符号的正则表达式
punctuation_regex = '[,.;"]+'
定义词典
这是一个map, 键是单词, 值是该单词出现在的所有文档编号的列表1
dictionary = {}
定义当前处理的文档编号
1 | # 当前处理的文档编号 |
2 生成词典
1 | # 依次处理每篇文档 |
3 生成 word-document 矩阵
即生成上述的矩阵 $X$ 。1
2
3
4
5# 生成word-document矩阵
X = np.zeros([len(keywords), currentDocId])
for i, k in enumerate(keywords):
for d in dictionary[k]:
X[i,d] += 1
4 奇异值分解
这里svd函数得到的 $U$, $V$ 与前述的变量$U$, $V$一一对应,$sigma$是前述的 $\sigma$ 对角线元素组成的一维矩阵。1
2
3
4
5# 奇异值分解
U,sigma,V = linalg.svd(X, full_matrices=True)
print("U:\n", U, "\n")
print("SIGMA:\n", sigma, "\n")
print("V:\n", V, "\n")
5 降维
代码中降到了2维。1
2
3
4
5
6# 得到降维(降到targetDimension维)后单词与文档的坐标表示
targetDimension = 2
U2 = U[0:, 0:targetDimension]
V2 = V[0:targetDimension, 0:]
sigma2 = np.diag(sigma[0:targetDimension])
print(U2.shape, sigma2.shape, V2.shape)
6 画图
1 | # 开始画图 |
LSA结果分析
这里我们需要注意的是,我们在衡量单词与单词、文档与文档间的相似度时,应该看得是两个向量的夹角,而不是点的距离,夹角越小越相关。
最终结果与所有点的坐标见下图。红线是额外画得辅助线。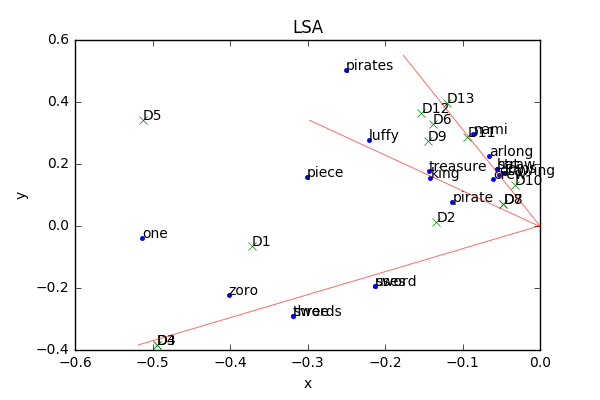
我们可以看到D1,D2,D3,D4四篇关于zoro的文档的向量之间的夹角都很小,且与关键词zoro、three、swords、sword、uses之间的夹角都很小(D3,D4与这些词夹角更小),这是因为D3和D4都提到了zoro使用三刀流,D1、D2提到了zoro但没提到三刀流。同理,我们可以看到luffy那条红线上是在讲路飞是要成为海贼王的男人,nami那边则提到了阿龙以及娜美的梦想是绘制世界航海图。从这些结果上可以看到LSA在进行语义分析时是有不错的结果的。
我们还能看到one和piece两个单词的位置,在关于luffy、zoro和nami的文档中均有可能出现one piece这两个词,一方面原因one piece是海贼王漫画的英文名很可能会在其中任何一个角色的文档中出现,表示大秘宝,另一方面,one这个词也可以表示一,zoro也会使用一刀流的描述中也出现了one这个单词。而LSA则会对于这些潜在的概念进行一个折衷,坐标位于zoro、nami、luffy三个主题之间,因此我们说LSA在对于一词多义的问题上并不能完美解决。
参考资料
1 Indexing by Latent Semantic Analysis by Scott Deerwester
完整代码已托管至 github